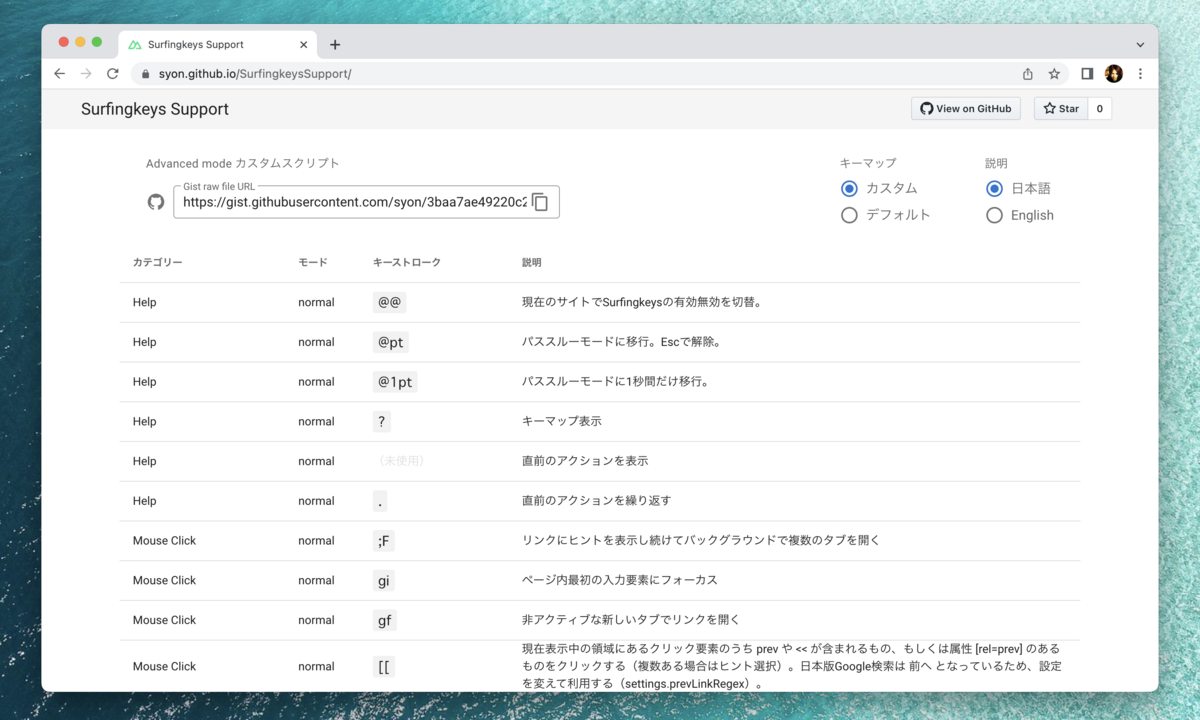
2023-05-06 ブラウザをキーボード操作する拡張機能『Surfingkeys』の全コマンド解説とキーマップ変更方法 キーボード JavaScript GitHub Surfingkeys Support Surfingkeysの全コマンドを翻訳・解説したサイトを作りました。 また、おすすめのキーマップ紹介とオリジナルのキーマップに変更する方法をご紹介します。 続きを読む
2022-04-29 SVG勉強した流れを残したよ zenn.dev SVGのベジェ曲線の基礎から試しながらだんだん応用して進化していく様子をステップごとに区切って残しました。 その中身はこの Zenn の記事にまかせて、ここでは苦労ポイントみたいなのを書いておきます。 続きを読む
2020-05-09 声で家電操作!アレクサとGoogleホームをNature Remoなどと連携した実例を紹介 スマートディスプレイを買いました Amazon Echo Show 5 Google Nest Hub 続きを読む